
89 tickets can feel louder than 8,900. That’s the trap. You felt a version of this this week: one ugly escalation hijacked the roadmap conversation, while the broader pattern sat quietly in the queue. That’s exactly where confidence-weighted prioritization earns its keep.
It’s usually not a data problem. It’s a ranking problem. Same thing with CX reviews that look rigorous on paper but are really just anecdote management with nicer charts.
Key Takeaways:
- Confidence-weighted prioritization works when you score issues on four things at once: volume, severity, business impact, and confidence in the signal.
- If an issue shows high volume but low confidence, hold it out of the sprint and validate first.
- If an issue shows moderate volume, high churn risk, and high confidence, it usually deserves faster action than a louder but fuzzier complaint.
- Scores alone won't tell you what to fix. Drivers, tags, and ticket evidence do.
- Sampling weakens prioritization because it hides edge cases and overstates whatever happened to be reviewed.
- A good operating rule: only escalate issues above a fixed score threshold and only after a ticket-level evidence check.
- Backtesting your prioritization model against closed fixes is the fastest way to see if you're shipping the right work.
Why Most CX Prioritization Breaks Before Engineering Even Starts
Confidence-weighted prioritization is just a way to rank support issues by likely value, not noise. You combine issue size, customer harm, business impact, and how confident you are that the pattern is real. That sounds obvious. Nobody's checking whether the last part is actually there.
![]()
The loudest ticket wins too often
A support lead at 3:42 PM on Thursday is in Zendesk, copying quotes into a Google Doc before the 4 PM product review. They found 17 angry billing tickets this week, 9 onboarding complaints, and 3 churn threats from enterprise accounts. The problem isn't that they missed something obvious. The problem is that they have no defensible way to compare those buckets against the other 4,971 conversations nobody read.
At low volume, you can survive on instinct. At 5,000 tickets a month, instinct turns into a bad microphone: it amplifies whatever squealed last. Confidence-weighted prioritization is the mixer board. It turns the noise down, pulls signal forward, and keeps one dramatic complaint from sounding like the whole crowd.
That’s why volume-only triage fails. Ticket count is one signal. Not the signal.
Scores create false confidence when they have no drivers behind them
CSAT dropped. Sentiment dipped. Effort looks worse this month. Fine. What do you do with that?
A score tells you the building is warm. It doesn't tell you which room is on fire. If you can't connect the change to a driver, a tag, or a repeated pattern in conversations, your next move is guesswork.
There’s a reason leaders like scorecards. Execs do need a fast read, and that part is fair. The miss happens when score-watching replaces investigation. Then teams fund fixes for symptoms, not causes, and confidence-weighted prioritization becomes fake precision with a spreadsheet attached.
Use one hard gate here: if a trend cannot be explained by the top 3 drivers behind it, it is not ready for prioritization. No exception unless the issue is tied to revenue loss or regulatory risk.
Sampling makes weak evidence look stronger than it is
What looks efficient in review meetings often produces the worst prioritization downstream. Read 50 tickets. Spot a pattern. Declare a trend. Done. Except not really.
If you're sampling under 10% of monthly ticket volume, treat any issue ranking as provisional unless it also appears in a second source like churn notes, escalation logs, or repeated high-effort conversations. If you're sampling under 5%, don't use that sample to set engineering priority by itself. Use it to form a hypothesis. Nothing more.
That sounds strict, and yes, full review is slower up front. Fair. The tradeoff is worth it because a bad sprint decision is slower than a careful validation pass. Teams rarely lose time by checking evidence. They lose it by shipping fixes for the wrong thing.
We were surprised how often teams confuse “I saw it several times” with “this is broadly happening.” Those aren't the same thing. One is memory. One is evidence.
The fix starts when you stop asking, “What looks bad?” and start asking, “What deserves a high-confidence score?” If that question feels annoyingly practical, good—the next section is where confidence-weighted prioritization stops being a slogan and becomes a working filter.
The Real Problem Is Missing Confidence, Not Missing Complaints
Most teams already have more complaints than they can action. What they don’t have is a repeatable way to decide which complaints deserve engineering attention. Confidence-weighted prioritization fixes that by forcing teams to score not just pain, but certainty.
A reproducible score needs four inputs, not one
A working confidence-weighted prioritization model should include at least these four inputs:
- Volume: how often the issue appears in a fixed time window
- Severity: how bad the customer experience looks inside those tickets
- Business impact: what the issue likely affects, like churn risk, effort, expansion, or retention
- Confidence: how certain you are that the pattern is a true pattern, not tagging noise or a one-off spike
If one of those is missing, you get distortion. High volume without severity creates busywork. High severity without volume can overreact to edge cases. Impact without confidence turns into executive storytelling.
A simple starting formula is: Priority score = (volume score × 0.35) + (severity score × 0.20) + (business impact score × 0.30) + (confidence score × 0.15)
Not sacred. Just useful. A B2B company with a handful of large accounts may want business impact closer to 0.40. A high-volume consumer support org may weight volume more heavily. Still, keep one non-negotiable rule: if confidence is zero, cap the final score at 60 out of 100 no matter what the other numbers say. That single cap prevents the most common failure mode in confidence-weighted prioritization—promoting noise because the volume column looked impressive.
Confidence has to be measured, not assumed
How do you know whether your confidence score is real or just borrowed certainty from a meeting? Ask five questions before an issue moves up the list:
- Does it appear in at least 30 tickets in the last 30 days, or in at least 2% of total volume?
- Does it show up across more than one customer segment, queue, or agent group?
- Do the tags or driver labels stay stable when you review a random set of 10 tickets?
- Does the trend persist for at least 2 consecutive reporting periods?
- Does the evidence include direct customer language pointing to the same underlying cause?
Give an issue high confidence only if at least 4 of those 5 are true. If only 2 or 3 are true, score it as medium confidence and validate before escalation. If fewer than 2 are true, don’t send it to engineering yet.
Let’s pretend an onboarding complaint appears in 42 tickets. Sounds urgent. Then you inspect 10 of them and realize 6 are really billing confusion, 2 are login failures, and only 2 are actual onboarding friction. Your volume number was real. Your pattern definition wasn’t. Confidence-weighted prioritization saves the sprint by catching the category mistake before engineering inherits it.
The hidden link between confidence and engineering trust
Product teams don’t hate support feedback. They hate fuzzy escalation.
When engineering gets three “urgent” requests in a month and one turns out to be noise, trust drops fast. Then even the strong signals start getting challenged. Same thing with PMs who got burned by weak evidence before. They ask for more proof, support feels ignored, and the loop slows to a crawl.
This is the part people miss: confidence-weighted prioritization is not only an analytics decision. It’s a trust contract between support, product, and engineering. The cleaner your confidence rules, the shorter the debate. The shorter the debate, the faster real work moves.
Now the practical question shows up. If confidence is the missing input, how do you turn confidence-weighted prioritization into a weekly operating system instead of another nice idea?
How to Build a Confidence-Weighted Prioritization Model That Holds Up
A confidence-weighted prioritization model works when it is boring enough to repeat and sharp enough to say no. If every issue can still be argued into the sprint, you don’t have a model. You have a meeting habit with math on top.
Start with a scoring table your team can maintain weekly
Use a 100-point model with fixed bands. If your support lead cannot update it in 20 minutes, it is too complicated to survive month two.
Volume: 0 to 25 points
1% of volume or less = 5
1% to 3% = 10
3% to 5% = 18
Over 5% = 25
Severity: 0 to 20 points
Mostly neutral friction = 5
Repeated frustration or high effort = 10
Clear negative sentiment or unresolved outcome = 15
Churn threats, repeated failures, or severe effort = 20
Business impact: 0 to 35 points
Low-value segment, low retention relevance = 5
Mixed segment exposure = 15
High-value accounts or strong effort burden = 25
Clear retention, churn, or expansion impact = 35
Confidence: 0 to 20 points
Weak pattern, unstable tagging, single-source = 5
Some consistency, partial validation = 10
Repeated pattern across segments with ticket review = 15
Stable, validated, multi-period pattern with clear evidence = 20
Then set action thresholds:
- 80+: create engineering ticket this sprint
- 65-79: assign owner, validate root cause, prep fix recommendation
- 50-64: monitor weekly, gather more evidence
- Under 50: don't escalate yet
The threshold is the point. Without one, confidence-weighted prioritization collapses back into negotiation.
Use ticket review to calibrate the model, not replace it
Still necessary, human review is. Just not everywhere.

A good weekly workflow looks like this:
- Group tickets by Driver, Canonical Tag, or Raw Tag
- Review 5 to 10 underlying tickets for each pattern
- Check whether the tags, driver, sentiment, effort, churn risk, and customer language actually line up
That review step catches merged problems, broken taxonomy, temporary spikes, and agent workflow weirdness. Quiet wreckers. Left alone, they distort confidence-weighted prioritization from the inside.
Some teams want full automation, and the appeal is obvious. Fast, scalable, clean. For very high-volume queues with stable taxonomy, that can work. For roadmap calls, though, a fast human validation pass still pays for itself. You lose 30 minutes. You avoid two weeks of engineering time on a false pattern.
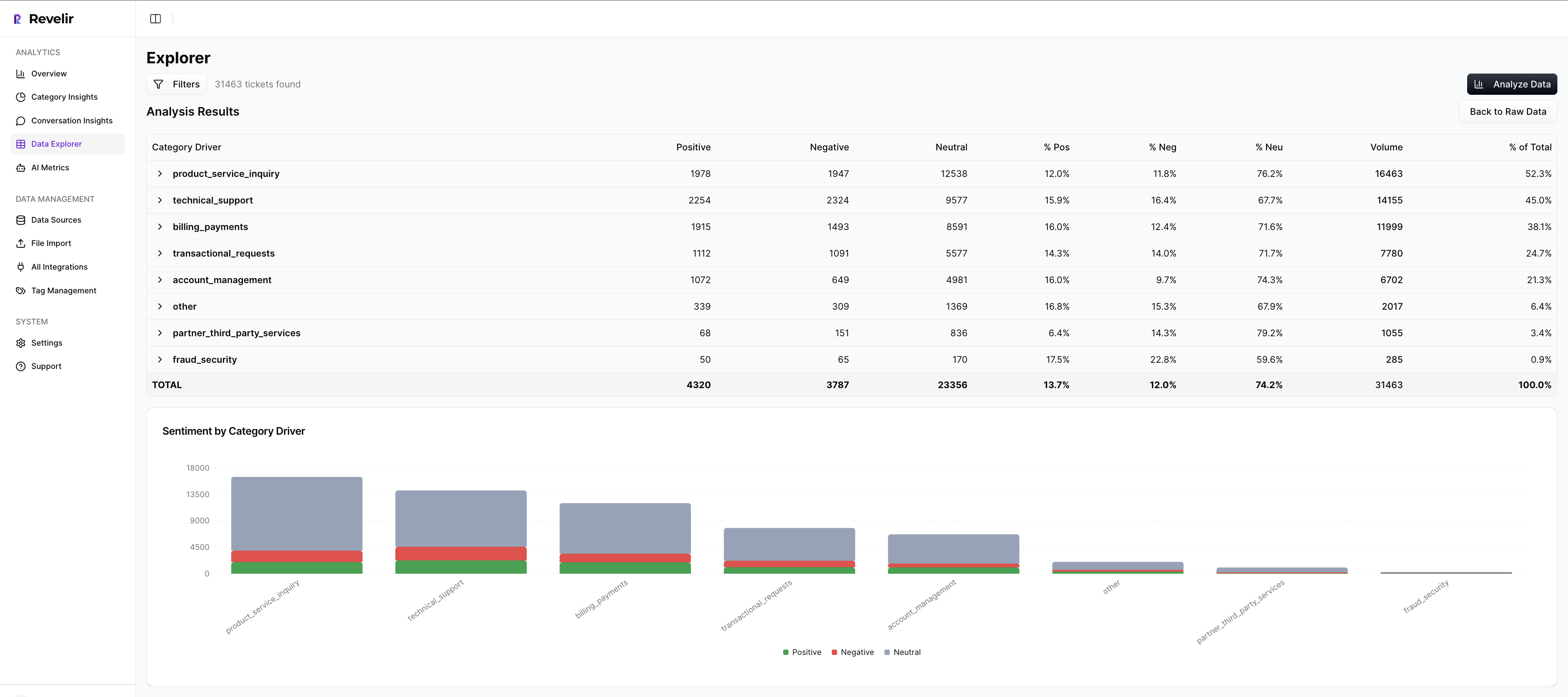
This is where Revelir AI helps without pretending to replace judgment. In Analyze Data, you can summarize sentiment, churn risk, effort, and custom metrics by dimensions like Driver or Canonical Tag, then click straight into the underlying conversations. In Data Explorer, every ticket stays visible as a row with the columns you need to sort, filter, and inspect. Revelir AI also gives you evidence-backed traceability, so every aggregate number can be checked against the source transcript instead of defended with hand-waving.
Separate signal from storytelling
A model only works if the underlying evidence is easy to inspect. Otherwise every score turns into an argument about whether the pattern is real.

That is why full-coverage processing matters. Revelir AI processes 100% of ingested tickets, whether they come in through the Zendesk integration or a CSV upload, so you are not basing decisions on a sample that misses the messy edge cases. The hybrid tagging system helps here too: Raw Tags surface the granular language customers actually use, while Canonical Tags give you a cleaner layer for reporting and repeatable analysis.
When a pattern looks important, open the ticket-level detail before you push it into planning. Conversation Insights gives you the full transcript, AI-generated summary, tags, drivers, and AI metrics for each conversation. That makes it easier to validate the pattern, pull quotes, and explain the issue in plain English to stakeholders who do not live in the queue.
Keep the model simple enough to survive contact with reality
The best prioritization model is not the smartest one. It is the one your team will still use after the quarter gets busy.

Start with a fixed scoring table. Review the evidence behind the top patterns. Use metrics like sentiment, churn risk, customer effort, and outcome as inputs, not as substitutes for judgment. If you need more context, define Custom AI Metrics in Revelir AI to classify the questions that matter in your business, then use those results as columns in filtering and analysis.
And once you have a pattern worth sharing, export the structured metrics through the API into the reporting or BI workflow your team already trusts. Revelir AI is strongest when it gives you a cleaner signal, a clearer audit trail, and faster access to the underlying conversations.
Proving the Model Works Before You Bet a Quarter on It
Confidence-weighted prioritization should not win because it sounds smarter in meetings. It should win because it predicts better outcomes than the old way. That means backtesting, side-by-side comparison, and a clear eye on drift.
Backtest the last 90 days before changing your workflow
Pull the top 15 issues your team escalated in the last quarter. Score them again using the new model, based only on the data available at the time. Then compare the rankings to what actually happened after the fix or non-fix.
Look for three things:
- Did higher-scored issues lead to bigger drops in repeat complaints?
- Did they produce measurable improvement in churn risk, effort, or negative sentiment?
- Did low-confidence issues underperform when they were escalated anyway?
If your top quartile of scored issues doesn’t outperform the bottom quartile by at least 30% on a downstream metric, don’t roll the model out yet. Keep tuning. Confidence-weighted prioritization should earn trust the same way any other operating model does: by beating the baseline.
Run an A/B operating test between teams or issue classes
Want a cleaner proof than a retrospective? Split the operating method for 4 to 6 weeks.
One group uses the old method: anecdotes, volume, and ad hoc review. The other uses confidence-weighted prioritization with fixed thresholds. Then compare:
- engineering tickets created
- issues reopened after “fix”
- customer effort changes
- repeated complaint volume
- time spent in prioritization meetings
A strong result isn’t just fewer tickets. It’s better tickets. Fewer noisy escalations, more fixes that actually move something. A reasonable target is roughly 50% fewer low-quality escalations to engineering and about 30% more impact per sprint from the fixes that do get prioritized.
Watch for failure modes that signal your model is drifting
Models drift quietly. Usually through definitions, not math.
Three red flags:
- Confidence scores keep rising across the board. That usually means reviewers got lazy or taxonomy got too broad.
- One driver starts swallowing everything. If “billing” suddenly covers six different root causes, prioritization quality drops.
- High-scoring issues stop producing measurable results. That’s your sign to tighten thresholds or reweight business impact.
Think of the model like QA for a support taxonomy. When the labels blur, the ranking lies. When the ranking lies, confidence-weighted prioritization becomes theater. Review the misses, not just the wins. That’s where the recalibration lives.
And once the model is stable, the next challenge isn’t theory. It’s operational drag. How do you run confidence-weighted prioritization without living in spreadsheets all week?
How Revelir Makes Confidence-Weighted Prioritization Usable
Confidence-weighted prioritization only works if the inputs stay stable, traceable, and easy to inspect. That’s where most teams stall. The logic is sound; the workflow is miserable. Revelir AI closes that gap by giving teams full-ticket coverage, structured analysis, and evidence they can bring into real prioritization meetings.
Full coverage changes the confidence math
Revelir AI processes 100% of ingested tickets through Full-Coverage Processing, so your confidence score doesn’t start from a sample. That changes the math immediately. You’re not inferring a pattern from a thin slice and pretending it represents the whole queue.
If your tickets live in Zendesk, Revelir AI can bring in historical and ongoing conversations through the Zendesk Integration. If you want to test the model on exports or another helpdesk, CSV Ingestion gives you a path without changing your support stack. That matters because confidence-weighted prioritization gets weaker the minute coverage is partial from day one.
Data Explorer and Analyze Data make the ranking practical
Revelir AI's Data Explorer gives you a pivot-table-like place to filter, group, and inspect tickets across sentiment, churn risk, effort, tags, drivers, and custom metrics. That's the day-to-day workspace for ranking issue clusters, checking segment spread, and seeing whether a pattern really holds.
Then Analyze Data gives you grouped analysis by Driver, Canonical Tag, or Raw Tag with summaries and linked underlying tickets. Before that, a team says, “billing seems bad lately.” After that, they can compare which billing-related drivers show the worst effort or churn risk, how large those clusters are, and whether confidence-weighted prioritization should push one issue above another.
Traceability keeps the model honest
This part matters in real meetings. Revelir AI ties every aggregate number back to source conversations through Evidence-Backed Traceability, and Conversation Insights lets you drill into transcripts, summaries, tags, drivers, and AI metrics at the ticket level. When somebody challenges the ranking, you don’t defend it with opinions. You open the evidence.
The Hybrid Tagging System helps here too. Raw Tags surface what the conversations are actually saying, Canonical Tags give you reporting structure, and Drivers help answer the bigger “why” question leadership usually asks. Add the AI Metrics Engine and Custom AI Metrics, and confidence-weighted prioritization becomes easier to maintain because the model can mirror your business language instead of generic sentiment alone.
If you want to see what that looks like in practice, Get started with Revelir AI (Webflow).
Better Prioritization Starts When You Stop Trusting Noise
Confidence-weighted prioritization is really about discipline. You stop rewarding the loudest anecdote and start rewarding the strongest evidence. That’s how teams cut noisy escalations, protect engineering focus, and get more impact from every sprint.
Scores aren’t strategy. The why behind the score is. Once your team can see the driver, inspect the tickets, and trust the confidence behind the ranking, prioritization gets a lot less political and a lot more useful.
Frequently Asked Questions
How do I validate a high confidence score?
To validate a high confidence score, you should check if the issue appears in at least 30 tickets over the last 30 days or 2% of total volume. Ensure it shows up across multiple customer segments and that the tags remain stable when reviewing a random set of tickets. If at least four of the five validation questions are true, you can confidently escalate the issue. Using Revelir AI's Analyze Data feature can help you summarize metrics and link back to the underlying tickets for thorough validation.
What if I have low volume but high severity issues?
If you encounter low volume but high severity issues, it's essential to validate them before prioritization. You can use Revelir AI's Data Explorer to filter and inspect these tickets closely. Check for patterns in customer language and any related tags that might indicate a broader issue. If the issue is tied to significant business impact, it may still warrant action, but be sure to gather enough evidence to support escalation.
Can I use Revelir AI for CSV imports?
Yes, you can use Revelir AI for CSV imports. If you want to analyze historical data or run a one-off analysis, simply export your tickets from your helpdesk as a CSV file. Then, upload them via the Data Management section in Revelir. The platform will parse the transcripts and apply its full tagging and metrics pipeline, allowing you to gain insights from your data without needing to change your current support stack.
When should I escalate issues to engineering?
You should escalate issues to engineering when they score 80 or above on your confidence-weighted prioritization model. For scores between 65 and 79, assign an owner to validate the root cause and prepare a fix recommendation. Use Revelir AI's ticket review capabilities to ensure you have solid evidence backing your decision before escalation. This helps maintain trust between support and engineering teams.
Why does sampling weaken prioritization?
Sampling weakens prioritization because it can hide critical edge cases and lead to a false sense of certainty. When you only review a small percentage of tickets, you risk missing important patterns that could indicate larger issues. Revelir AI addresses this by processing 100% of ingested tickets, ensuring that your insights are based on comprehensive data rather than a biased sample. This full coverage allows for more accurate prioritization and decision-making.