

Early-stage teams do not need labels to get value from low-data churn detection. You can ship a useful detector this week with rules you can explain and defend, then tighten it with evidence from real tickets. It is usually not the model that blocks you. It is the lack of a traceable signal people trust.
So let’s set a clear bar. Use full-population data, not samples. Anchor on the next 30 days, not a vague future. Produce alerts with the exact words customers used and the ticket links attached. If a CSM can’t see the why in seconds, the alert is noise. That is the standard we are working toward with low-data churn detection.
Key Takeaways:
- Ship a simple, explainable rule set for low-data churn detection this week, then iterate with evidence
- Define churn risk for the next 30 days so CSMs act on rescues, not theory
- Prioritize transcript cues and drivers over thin usage scores, then validate by clicking into tickets
- Measure precision with 20 to 50 ticket checks per rule before rollout, then tune thresholds
- Combine signals conservatively at first to avoid false-positive waste and morale hits
- Make traceability non-negotiable so leadership sees proof, not anecdotes
- Use Revelir to process 100% of conversations, validate in minutes, and route risk with context
Stop Waiting For Labels: Low-Data Churn Detection You Can Ship This Week
You can ship low-data churn detection this week by writing three or four explainable rules, running them across all tickets, and tying each alert to the next 30 days. Use conversation signals and billing events you already have. Aim for high precision and fast trust, not a perfect model you cannot validate.
Why Speed Beats Perfection In Early-Stage SaaS
Speed wins because the cost of late detection is real, and it compounds. While you wait for labels, you miss saves you could have made with clear, near-term rules. It is usually the urge to chase accuracy without evidence that slows teams. Start small, prove precision, then expand with confidence.
Write rules that a CSM can understand at a glance, like “explicit cancel intent in transcript” or “payment failure within 14 days of renewal.” Run them across your full backlog to spot patterns quickly. When someone asks “why did we flag this account,” you click the ticket and show the line that triggered the rule. Nobody’s checking your model diagram in that moment. They are checking the evidence.
You will make mistakes early. That is fine if the mistakes are visible and easy to correct. Keep thresholds tight, keep coverage focused on rescues, and recalibrate weekly. The wrong goal is broad recall without proof. The right goal is a short list of real risks that CSMs trust.
What Counts As Churn Risk In Your Next 30 Days?
Churn risk should mean “act now” in your world, not a vague probability. Define it for an actionable window so the team stays focused. Examples are concrete and defensible: explicit cancel intent, unresolved escalation ahead of renewal, payment failures near due dates, or repeated refunds that never stick.
Turn each example into a rule with clear fields, thresholds, and a reason string. “Cancel intent in transcript” is a trigger, but “cancel, downgrade, or leave plus account name in the same thread” is stronger. Same thing with billing. “Payment failed within 14 days of renewal” beats “payment failed sometime last quarter.” Tight windows prevent drift and cut noise.
Keep the set small at first. Three or four rules is enough to learn fast, tune thresholds, and build trust. More rules without validation only add cost. You can always add depth after CSMs confirm the first batch is catching real risk.
What Signals Do You Already Have Today?
You have more signal than you think, even without engineering work. Start with support transcripts, agent tags, AI churn risk flags, sentiment, effort, refund metadata, plan tier, renewal date, and payment events. Document where each field lives, what it is called, and how fresh it is. Gaps will show up as you write rules.
List the fields in a simple sheet so everyone uses the same names. This alone prevents wrong assumptions that waste a week. If a field is partial, say so. You can still move. Run an initial pass on the signals that have coverage today, then tighten the rest as you learn.
If you need more context, pull a small, recent CSV export and check a dozen tickets for how customers phrase cancel intent or billing confusion. Those phrases become patterns in your rules. Evidence beats theory here. Always.
Evidence Over Models: Reframing Low-Data Churn Detection Around Conversations
Early-stage churn detection should center on conversations and traceable evidence, not opaque models or thin health scores. Transcripts reveal intent, friction, and reasons you can act on. Write explainable rules and insist on a direct path from each alert to the exact words customers used.

Conversations Beat Usage Metrics For Early Risk
Usage drops matter, but they are often lagging and ambiguous at small data scales. Conversations state intent, expose friction, and name the reason that drives a plan. Prioritize transcript cues, frustration spikes, and drivers over a single health score. You can validate these rules in minutes by opening the tickets behind them.
If you want a primer on framing the problem, this overview on Predicting churn in B2B SaaS 101 lays out common approaches. Read it as context, then build your own rules around the language your customers actually use. Without that step, you risk optimizing a score that does not explain why customers leave.
Rules built on conversations earn adoption because they reflect reality the team recognizes. People remember the quote, not the chart. When you connect the two, action follows.
Why Do Explainable Rules Earn Trust?
Explainability is the difference between a tool people use and a dashboard they ignore. Each rule should come with a human-readable reason and a link to the transcript. In reviews, you can show two or three quotes that represent the pattern. People trust signals they can audit.
Opaque scores stall in meetings. Someone will ask “why is this account red,” and if you cannot show the conversation, the room loses confidence. That is a common failure path. Keep your rules simple and your traceability tight. It prevents the wrong fix and protects the team from rework.
When you get pushback, invite it. Then click into the ticket together. Shared evidence turns debate into decisions. That is the point.
The Cost Of Delay And Noise In Low-Data Churn Detection
Delay and noise carry a real cost. Manual review steals hours for a partial view, false positives drain CSM attention, and late detection means lost renewals. Automate detection, validate with ticket drill-downs, and tune for precision so effort goes to rescues, not cleanup.
Manual Review Math That Breaks Your Week
Let’s pretend you handle 800 tickets this month. Sampling 10 percent at three minutes each costs about four hours for a partial view. Full manual review would take 40 hours and still miss subtle churn cues. That is a direct cost, and it delays interventions you could have made this week.
Sampling bias adds another layer of risk. Loud anecdotes dominate, while quiet but important friction in onboarding slips by. Teams try to compensate with ad hoc reviews during spikes, which are reactive and stressful. You end up tired and still wrong.
Shift the math. Automate detection across 100 percent of conversations, then review the flagged subset with proof attached. If you want a reference point on monitoring at speed, see this take on real-time churn monitoring for SaaS companies.
The False Positive Tax On CSMs
If your detector floods the queue with weak alerts, triage time explodes and trust collapses. A dozen false alarms per rep per week can waste hours and bury the real risks. That is when alerts get ignored and morale dips.
Favor high precision at the start. Add cool downs. Attach evidence so a rep can decide in seconds. If you are not sure, tune thresholds and try again. Noise is expensive. Precision pays for itself.
CSMs will tell you, plainly, when the signal is off. Listen, adjust, and document what changed. Adoption follows results.
What It Feels Like To Fly Blind On Churn Risk
Flying blind feels like late nights stitching quotes, defensive meetings without proof, and a team losing faith in alerts that are often wrong. A traceable, precise signal fixes that. It replaces guesswork with shared evidence and shortens the path from pattern to plan.
The 11 PM Rework Spiral
You are rewriting emails and combing threads at 11 pm to rebuild the story behind a renewal at risk. There is no single view, just scattered notes and screenshots. The next morning, leadership asks for answers. Without a consistent signal and traceable examples, you guess, you miss nuance, and the cycle repeats.
It is not sustainable. Quality drops. Fatigue grows. A clear rule hit with a link to the conversation changes that whole arc. You show the quote, agree on the reason, and move to next steps. Simple, visible, repeatable.
We learned this the hard way too. It is usually not effort that is missing. It is the evidence.
Stakeholder Doubt And Meeting Drag
When findings rely on anecdotes, leaders push back. Show me the proof. You open a spreadsheet and a few pasted quotes. Confidence fades. Projects stall, and teams default to safe, shallow fixes.
Tie metrics to transcripts and bring two or three representative examples. Debates shift from whether the problem exists to how to solve it. Meetings move faster. Decisions stick.
If you need an outside lens on survival math, this guide on SaaS churn rate survival frames the stakes. Then come back to your tickets. Your evidence is already there.
The Rule-First System For Low-Data Churn Detection That CSMs Trust
A rule-first system that CSMs trust starts with a fast signal inventory, a small set of high-precision heuristics, quick precision checks on real tickets, and safe combinations that avoid noise. Keep the window to the next 30 days and make traceability a hard rule.
Inventory Signals: Conversations, Metadata, Billing Events
Start by listing what you already have. Support transcripts, agent tags, AI churn risk flags, sentiment, customer effort, refund metadata, plan tier, renewal date, payment failures, and escalation markers. Document field names, where they live, how fresh they are, and coverage. Shared language speeds rule writing and prevents rework.
Two quick passes help. First, skim a dozen fresh tickets to capture the exact phrases customers use for cancel intent or billing confusion. Second, confirm the presence of renewal dates and recent payment events for your top segments. These checks shape your first rules and keep them grounded in reality.
Do not wait for perfect data. Use what is present now, then expand coverage as you learn. Momentum matters.
Design 7 High-Precision Heuristics You Can Defend
Draft rules with clear triggers, thresholds, and cool downs. Keep them specific so they are easy to audit. Examples you can defend out loud:
- Explicit cancel or downgrade intent in transcript, confirmed by account name
- Two or more refunds in 60 days without durable resolution
- Payment failure within 14 days of renewal date
- Escalation plus no resolution after seven days
- Rising effort across two tickets in a month for the same account
- Silence after a high-effort resolution, no follow-up in five business days
- Repeated billing confusion by driver for the same plan tier
Break the tie in favor of precision. You can always add recall later. Each rule should produce a reason string that reads like a sentence, not a code. That helps CSMs move fast.
Validate And Combine Rules Without Adding Noise
Before rollout, score each rule’s precision on a small sample. Open 20 to 50 flagged tickets, label whether the risk is real, and capture a few quotes. Keep rules that hit 70 percent or better. Tweak thresholds or add context fields for the rest. Document results so everyone knows what changed and why.
Then combine signals conservatively. Start with simple logic that preserves precision:
- Require two independent rules within 30 days to trigger a high-priority alert.
- Or allow one severe rule plus a recent payment failure to trigger an alert.
- Add a seven day cool down after CSM contact to prevent repeat noise.
- Review a sample of combined alerts weekly and adjust weights as needed.
If you want more patterns to consider, see this roundup of SaaS churn risk strategies and a take on churn analysis mechanics. Read them for ideas, then validate with your tickets. Evidence first, always.
Ready for a light-touch tool to speed this workflow without changing your helpdesk? Learn More
How Revelir AI Makes This Low-Data Churn Detection Playbook Faster
Revelir accelerates this rule-first system by processing 100 percent of conversations, attaching Churn Risk, Sentiment, and Customer Effort to each ticket, and letting you validate in minutes. Data Explorer surfaces grouped patterns, Conversation Insights ties every metric to exact quotes, and drivers plus API export route risk to CSMs with context.
Full-Coverage Processing And The Churn Risk Metric
Revelir processes every conversation, no sampling, and assigns AI metrics like Churn Risk, Sentiment, and Customer Effort to each ticket. That gives your rules a consistent base that covers the whole population. The payoff is simple. You avoid the manual review math that wastes time and miss fewer early signals that cost renewals.
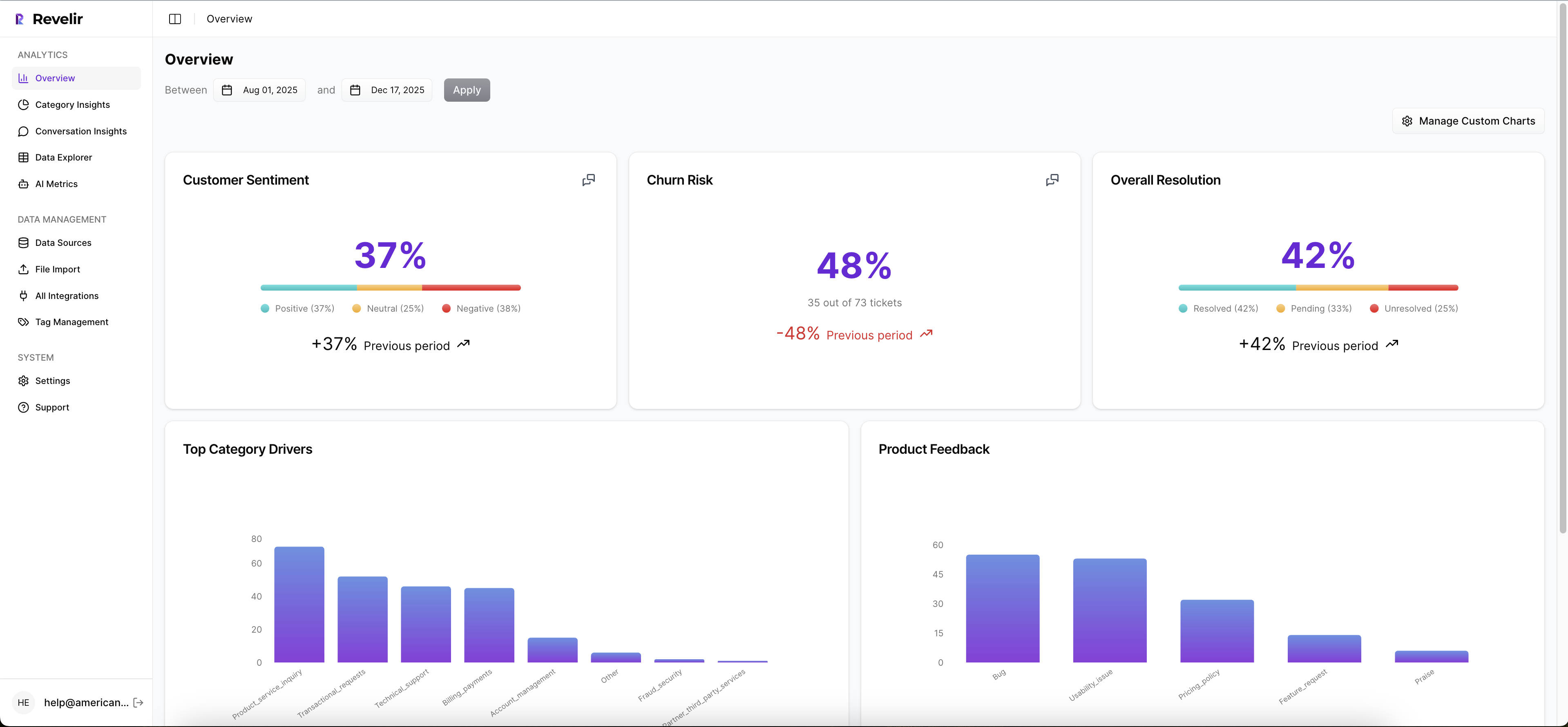
You also reduce trust debates. When someone asks “what is behind this metric,” you are one click from the transcript. That traceability calms the room and shortens the path from pattern to plan.
Validate In Minutes With Data Explorer And Conversation Insights
With Data Explorer, you filter by candidate rules, group by drivers or canonical tags, and spot patterns fast. Then you jump straight into Conversation Insights to read the transcript, review the AI summary, and confirm the rationale behind the alert. What used to take days becomes minutes, and you keep humans in the loop where it matters.

This is where you measure precision before rollout. Pull 20 to 50 flagged tickets per rule inside Revelir, label real risk vs not, and tune thresholds. The evidence is attached to every view, so nobody is guessing.
Drivers, Canonical Tags, And API Export For CSM Triage
Drivers and canonical tags turn noisy raw tags into leadership-ready categories. You can save views for high-risk drivers, share three quotes that capture the problem, and align on fixes. If you need to push the signal into your CRM, export metrics via API so at-risk accounts route to the right owner with reason attached.

This closes the loop from detection to triage without new systems or heavy change management. You keep your helpdesk, and you gain evidence-backed metrics that move work forward.
Revelir shows up as the intelligence layer over your tickets, not a replacement for your tools. That is how you avoid the false-positive tax and the late-detection cost that stalls teams.
Minutes to validation, not weeks of setup. That is what Revelir delivers.
Before you wrap, want a quick pass on your last 30 days of tickets with churn risk, drivers, and quotes ready for review? Learn More
Conclusion
Low-data churn detection is not a model project. It is a discipline. Define clear, near-term rules. Anchor them in conversations and billing events. Validate precision by clicking into the tickets. Combine signals conservatively. Then route risk with context so CSMs decide in seconds.
If you want to move faster, use a system that processes 100 percent of your conversations, ties every metric to a quote, and lets you measure precision in minutes. That is how you stop guessing, reduce waste, and save renewals you would otherwise miss.
Frequently Asked Questions
How do I set up low-data churn detection with Revelir AI?
To set up low-data churn detection using Revelir AI, start by writing three to four clear rules that define what churn risk looks like for your customers. Then, run these rules across all your support tickets. Make sure to tie each alert to the next 30 days so your Customer Success Managers can act promptly. You can use conversation signals and billing events already in your dataset to enhance the accuracy of your detection. Finally, validate your rules by checking 20 to 50 tickets to ensure they align with the real customer experiences before rolling them out.
What if I need to refine my churn detection rules?
If you need to refine your churn detection rules, start by analyzing the alerts generated from your initial setup. Use Revelir's Data Explorer to filter and group tickets by churn risk and sentiment. This will help you identify patterns or areas where your rules may be too broad or too narrow. You can then adjust your rules based on the insights gained from specific ticket examples. Additionally, consider incorporating feedback from your Customer Success Managers to ensure the rules are practical and actionable.
Can I track customer sentiment over time with Revelir?
Yes, you can track customer sentiment over time using Revelir AI. By utilizing the Analyze Data feature, you can select sentiment as your metric and group it by various dimensions, like date ranges or canonical tags. This allows you to visualize changes in sentiment and identify trends related to specific issues or time periods. You can also drill down into individual tickets to see the context behind sentiment fluctuations, helping you understand customer experiences better.
When should I intervene with high-risk customers?
You should intervene with high-risk customers as soon as they are flagged by Revelir's churn risk metric. When a conversation is marked with a churn risk signal, it's crucial to act quickly, ideally within the next 30 days. Use the insights from the Conversation Insights feature to understand the context of their issues. This way, you can tailor your outreach to address their specific concerns and potentially prevent churn.
Why does Revelir emphasize full-population data for insights?
Revelir emphasizes full-population data because it ensures that all customer interactions are analyzed, avoiding the biases and gaps that can occur with sampling. By processing 100% of your support tickets, Revelir provides a comprehensive view of customer sentiment, churn risk, and other metrics. This approach allows teams to make informed decisions based on complete data rather than assumptions, ensuring that insights are grounded in actual customer conversations.