

You don’t lose customers at renewal; you lose them in the weeks and months before it. The signals are sitting in your support conversations: frustration cues, downgrade intent, unresolved bugs resurfacing, contract questions. Most teams still sample and watch scores, then wonder why churn feels “sudden.” It wasn’t. You just didn’t measure the right things at the right depth.
Here’s the punchline. Sentiment alone won’t save you, and neither will a black‑box churn probability. You need explicit, auditable signals tied to quotes, with 100% coverage and a sane way to review them. Start with rules that a human would agree with in three seconds. Layer a lightweight model to catch gray areas. Keep everything traceable to the transcript. That’s the playbook.
Key Takeaways:
- Sentiment and sampling miss early churn cues; measure explicit, audit‑ready signals tied to quotes
- Start with deterministic rules (cancel intent, refund exploration, repeat failures), then add a small model for nuance
- Prioritize precision early to avoid noisy alerts that burn trust and time
- Build a simple score that explains itself: matched rules, evidence, and recency/severity
- Validate weekly with drill‑downs, adjust thresholds by segment, then broaden coverage
- Use full‑population analysis with traceability so leadership debates decisions, not data provenance
Why Sentiment And Sampling Miss Churn Signals In Conversations
Early churn risk hides inside conversation patterns that sentiment scores don’t capture. You’re looking for threat language, downgrade intent, refund exploration, and unresolved bugs reappearing. Sampling makes those patterns look rare when they’re not. Full coverage with traceable evidence turns vague worry into concrete, auditable risk signals that teams can act on.

The signals that sentiment alone cannot see
Sentiment is a blunt instrument. A customer can be “neutral” while negotiating a downgrade or asking how to terminate a contract. That’s risk in plain sight, just not “negative.” What you’re really chasing are durable signals: repeated handoffs, reauthentication loops, unresolved outcomes, and intent phrases that point to leaving, not venting.
We’ve all seen it. A polite enterprise admin asks about “shortening the term” after two weeks of failed SSO. No caps lock. No anger. High risk. Scores won’t flag it. Explicit patterns will. When you codify phrases like “cancel,” “downgrade,” “terminate,” and pair them with effort indicators (multi‑contact threads, escalation chains), you get risk that’s visible and defensible. For context on conversation‑level signal extraction, see this PLOS ONE study on conversation signal detection.
What does a high precision churn signal look like?
Think deterministic and auditable. “Customer requests cancellation terms,” “mentions competitor and switching timeline,” “asks for refund escalation after repeated failures.” Tie that to concrete context: unresolved ticket outcome, repeat contacts inside seven days, manager escalation. Then, show the quote. A CSM should be able to verify the alert in seconds.
Precision doesn’t mean perfection. It means your top‑priority alerts are rarely wrong, so people keep using them. Put the strongest patterns at the top of the list and keep the bar high. As validation proves out, widen the net. That’s how you avoid the early trap: lots of predictions, little trust.
Why you need 100 percent coverage and traceability
If you only sample, small signals stay invisible until they’re big and expensive. Coverage shows micro‑patterns early across segments you’d otherwise miss, new users, specific regions, particular product areas. Traceability protects trust. When leadership asks “show me,” you click into the exact transcript. Debate shifts from “is this real?” to “what do we do?”
Coverage and traceability also make your measurement layer repeatable. When each metric links to the ticket and quote, you can revisit decisions later without rewriting history. That’s the difference between winning an argument and building a system your org actually believes in.
Ready to skip the theory and see a working version of this approach? See how Revelir AI works.
From Black Box Scores To Evidence You Can Audit And Use
The real problem isn’t a lack of data. It’s black‑box scores that no one can defend when priorities are on the line. Start with explicit, explainable signals and a clean schema, then add a lightweight model to catch nuance. Keep every prediction tied to evidence and you’ll keep trust in the room.
What data do you need to start?
Inventory your sources and get the schema right before you write a single rule. You need full transcripts, timestamped turns, ticket metadata, requester and account identifiers, conversation outcomes, and historic churn labels at the account level. Canonical tags and drivers help you communicate patterns in leadership‑friendly language.
Optional segmentation fields, plan tier, region, lifecycle stage, pay off quickly. Clean structure beats “more data” every time. If your data doesn’t carry outcomes or identifiers, you can’t validate or activate. This is the foundation, cut corners here and you’ll fight your models forever.
Where traditional approaches go wrong
Teams jump to complex models too soon, then accept predictions they can’t explain. They conflate negativity with risk, overfit to convenience labels, and don’t keep an audit path. The result? Alerts that feel arbitrary. People stop listening. You end up back in ad‑hoc reviews and anecdote contests.
Flip the order. Codify precise signals first. Build your rule set around phrases, effort indicators, and outcomes you can verify. Only then add a small, transparent classifier for the gray zone. Research on hybrid approaches consistently shows that a rule‑plus‑ML stack outperforms either alone in noisy, imbalanced settings, see this Scientific Reports analysis of hybrid models.
How do you keep precision high without missing risk?
Lead with conservative rules for the costliest patterns. Use features you can explain: escalation count, repeated intents, unresolved outcomes, driver clusters. Then layer a calibrated model to catch softer cues. Keep thresholds segment‑aware; enterprise renewals aren’t the same as self‑serve trials.
Most important, preserve evidence. Every alert should list matched rules, model score, and links to representative quotes. When humans can audit in seconds, adoption sticks. When they can’t, it doesn’t matter how clever your model is.
The Cost Of False Alarms And Missed Risks
Noisy alerts burn time and credibility; missed early signals create downstream costs you can’t afford. Precision is not a luxury, it’s operational risk management. When you measure accurately and completely, you stop firefighting and start sequencing the right fixes.
The operational drag of noisy alerts
Let’s pretend your system flags 200 accounts a week and 70% are false alarms. If each review takes six minutes, that’s 14 hours gone, every week, before action. CSMs triage instead of coaching. Product tunes out. Leadership stops asking for the report. The backlog grows while real risk hides in the noise.
Start conservative. Weight recent, verifiable events higher. Defer ambiguous cases to a weekly review instead of paging on day one. Then, as your validation shows sustained precision, widen thresholds. You’ll protect calendars and keep the trust you need to scale.
The hidden impact of missed early signals
Missing a quiet early indicator is expensive. A refund loop that “looked small” turns into a renewal loss. A permissions bug during onboarding becomes an executive escalation. Each miss compounds: more support volume, more context switching, more rework. Dollars leave, and so does morale.
If you want the ROI math, a balanced view of churn prediction trade‑offs is discussed in this Hindawi paper on model precision and class imbalance. The headline for operators: the cost of acting on noise and the cost of missing risk both stack fast.
When An At‑Risk Account Slips Through
Everyone has a story about the account you “didn’t see coming.” You did. The signals were in the queue, just unstructured and unaudited. The fix is earlier, verifiable detection and a shared view of proof so teams move faster with confidence.
A 3am escalation that did not have to happen
Picture it. Enterprise account. Week two of onboarding. Repeated verification prompts, then an access failure during a live event. The customer goes dark, then escalates at 3am. If you trace the thread, it’s all there: unresolved outcomes, repeated contacts, early downgrade language. Nobody saw the cluster in time.
It’s avoidable. High‑precision flags, tied to quotes, would have put that account on a CSM’s radar days earlier. Even one targeted outreach could have averted the escalation and the renewal risk that followed.
What would good look like?
CSMs see verified risks grouped by driver, not a wall of tickets. PMs click into representative examples and ship targeted fixes. Leadership gets patterns with proof, so alignment happens in minutes, not meetings. The org trusts the measurement layer because anyone can audit it in seconds.
That’s the bar: fewer surprises, faster action, and evidence people believe. Once you feel that rhythm, the “we didn’t know” stories dry up, and the 3am pings get rarer.
A Practitioner Playbook For Hybrid Rule Plus ML Churn Detection
The winning pattern is simple: explicit signals first, small model second, validation always. You can implement this with the data you already have, as long as it’s structured and traceable. Here’s the practical way to run it.
Define high precision churn indicators
Codify clear, verifiable signals. Direct cancel or downgrade language. Refund negotiation and policy disputes. Competitor mentions with switching timelines. Critical bugs resurfacing after “resolved.” Then add effort signals: multi‑contact threads, escalation or reassignment chains, unresolved outcomes within a window.
Map raw phrases and tags to canonical categories and drivers so reports speak leadership’s language. This creates stable semantics your team can rally around. It also makes audits painless: same signal, same label, same rollup, every time.
Build rules and a priority scoring layer
Start with deterministic rules that capture the strongest evidence. Assign weights by severity and recency, direct cancel intent high, repeated failures medium, single policy complaint low. Aggregate these into a score per ticket and roll up to the account.
Make the score explain itself. Every alert should list which rules fired, when, and include the exact quotes. When a CSM or PM can scan and nod in under 10 seconds, your system will get used. If it needs a PhD to decipher, it won’t.
Train and calibrate a lightweight classifier to complement rules
Use historic churn labels and ticket‑level churn risk flags to train a small, interpretable model, logistic regression or linear SVM works fine. Engineer features you can explain: escalation count, repeated intent n‑grams, unresolved outcome flags, driver distribution. Calibrate thresholds to favor precision at first, then expand.
Hybrid stacks routinely outperform rules‑only or ML‑only approaches in messy, real‑world data. For a grounded view of model performance in imbalanced settings, see this Scientific Reports evaluation of hybrid classifiers. The lesson: simple, well‑tuned beats complex, opaque, especially when humans must act on the result.
How Revelir AI Supports The Hybrid Churn Playbook End To End
A rule‑plus‑ML approach needs three things: full coverage, traceability, and an analysis workflow that moves from pattern to proof without friction. Revelir AI was built for exactly this job, turning 100% of your conversations into evidence‑backed metrics your teams can trust and act on.
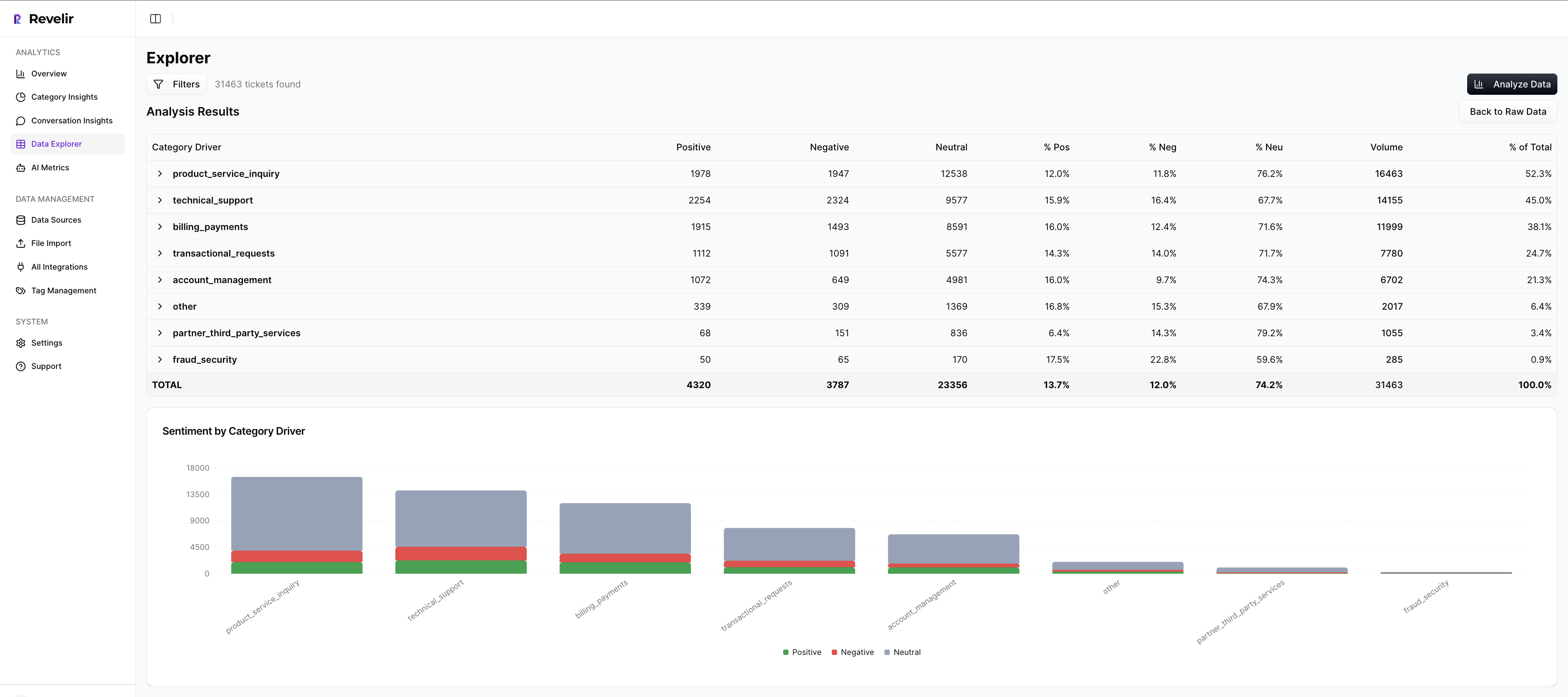
Full coverage metrics with ticket‑level traceability
Revelir AI processes 100% of tickets and computes metrics like churn risk, sentiment, and customer effort for every conversation. Every aggregate links back to the exact transcript and quote, so you can audit alerts instantly and keep signals credible. That traceability is how you avoid the “show me an example” stall in the meeting.
This addresses both failure modes we covered: missed signals from sampling and noisy alerts that collapse in review. With evidence attached by default, you protect precision and accelerate decisions. For a broader frame on evaluating conversational AI systems, this NIH review of conversation analysis methods is a useful reference point.
Data Explorer and Analyze Data for prioritization and proof
Use Data Explorer to filter churn‑risk conversations, slice by driver, and segment by plan or region. Run Analyze Data to quantify where risk concentrates, then jump into Conversation Insights to read representative tickets. You get volume, severity, and proof in one loop, exactly what a CSM, PM, and exec need to align.

This is where the rules‑plus‑ML playbook becomes operational. You can show “what’s happening,” “why it’s happening,” and “three quotes that make it real” in a single review. No stitching. No manual exports. Just decisions.
Custom AI metrics, canonical tags, and drivers that match your language
Bring your business language into Revelir AI. Define custom AI Metrics, refine canonical tags, and use drivers for leadership‑friendly rollups. Over time, mappings stabilize and reports get clearer. Your churn detection stays explainable because the categories mirror how your org talks about the business.

That continuity matters. It lets you evolve detection without breaking reporting, and it keeps audits simple. When the labels make sense to humans, adoption follows.
Still dealing with noisy, sample‑based reporting and one‑off audits? There’s a cleaner path. Learn More.
Conclusion
Here’s the thing. You don’t need a moonshot to detect churn early. You need explicit, auditable signals on every conversation, a small model for nuance, and a workflow that ties metrics to quotes in one click. Do that and you’ll trade 3am escalations for predictable, evidence‑backed reviews, and fewer surprises at renewal.
If you’re ready to operationalize this end‑to‑end, keep your existing stack and add the measurement layer that makes it work. Let Revelir AI handle the coverage and traceability while your team focuses on decisions. See how Revelir AI works.
Frequently Asked Questions
How do I identify the top drivers of churn risk?
To identify the top drivers of churn risk, start by using Revelir's Data Explorer. First, filter your dataset by 'Churn Risk = Yes.' Then, click on 'Analyze Data' and select 'Churn Risk' as your metric. Group the results by 'Driver' or 'Canonical Tag' to see which issues are most frequently associated with churn risk. This will help you pinpoint the specific areas that need attention, allowing you to address customer concerns proactively.
What if I want to validate insights with real conversation evidence?
You can easily validate insights by using the Conversation Insights feature in Revelir. After running an analysis in Data Explorer, simply click on any segment count to access the underlying conversations. This will show you the full transcripts, AI summaries, and associated metrics for each ticket. By reviewing these examples, you can ensure that your insights align with actual customer experiences, which is crucial for making informed decisions.
Can I customize the metrics used in Revelir?
Yes, you can customize the metrics in Revelir to match your business needs. You can define custom AI metrics that reflect specific aspects of your customer interactions, such as 'Upsell Opportunity' or 'Reason for Churn.' This flexibility allows you to tailor the insights generated by Revelir to better align with your organizational goals, ensuring that you capture the most relevant data for your analysis.
When should I review the sentiment analysis results?
It's a good practice to review sentiment analysis results regularly, ideally weekly or after significant product changes. By consistently checking the sentiment metrics in Revelir, you can identify trends and shifts in customer emotions. This proactive approach allows you to address emerging issues quickly, ensuring that you maintain a positive customer experience and reduce the risk of churn.
Why does Revelir focus on full conversation coverage?
Revelir emphasizes full conversation coverage because it eliminates the biases and gaps associated with sampling. By analyzing 100% of support tickets, Revelir ensures that you capture all relevant signals, including frustration cues and churn mentions. This comprehensive approach provides a more accurate and actionable understanding of customer sentiment and issues, enabling teams to make data-driven decisions that directly impact customer retention.